A Research-Based Tool
ROAR Scores are highly correlated with other standardized reading scores. Click to learn more about the multi-study validation process.

Rapid. Automated. Online.
Designed to be administered in the classroom or at home, students can take the ROAR on any computer or Chromebook connected to the internet.

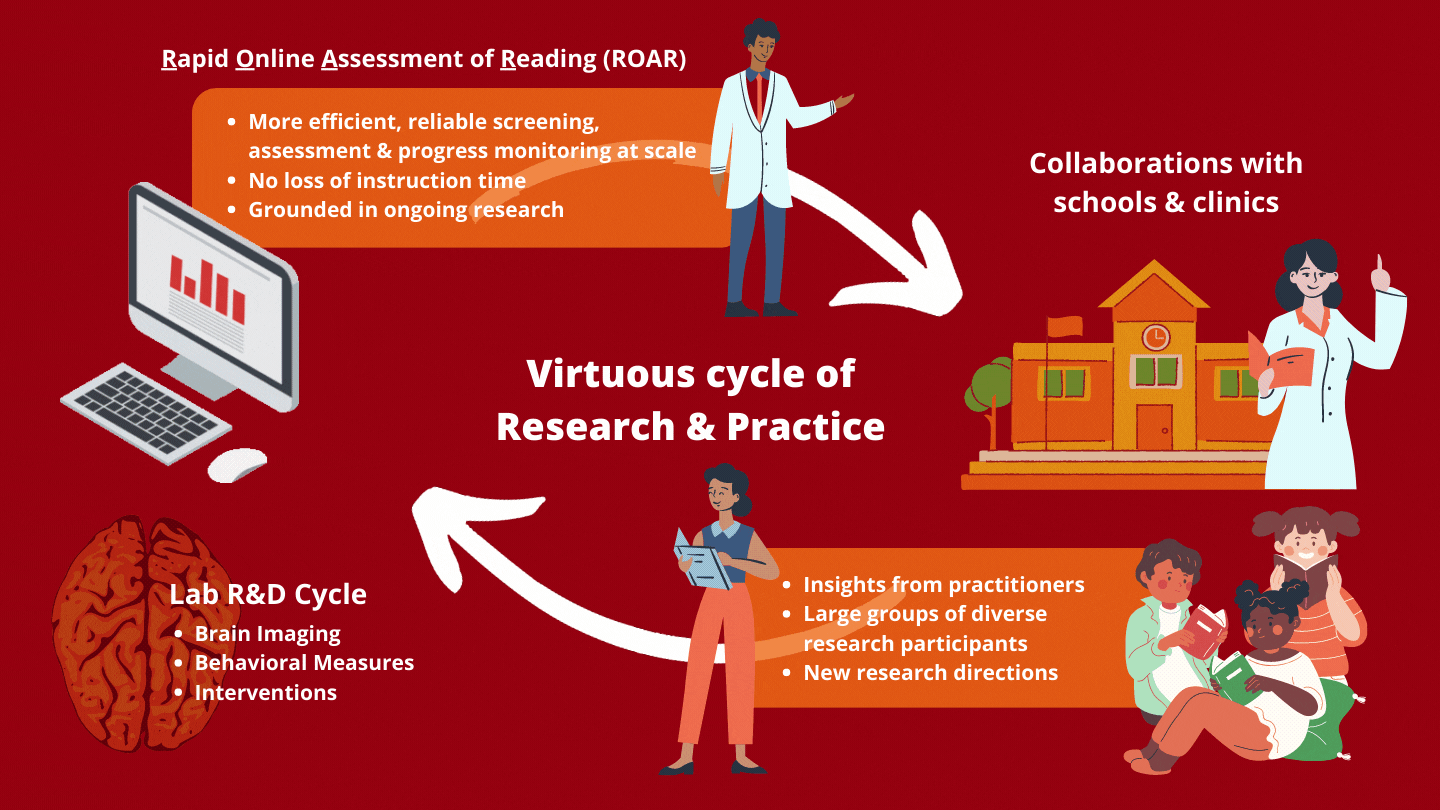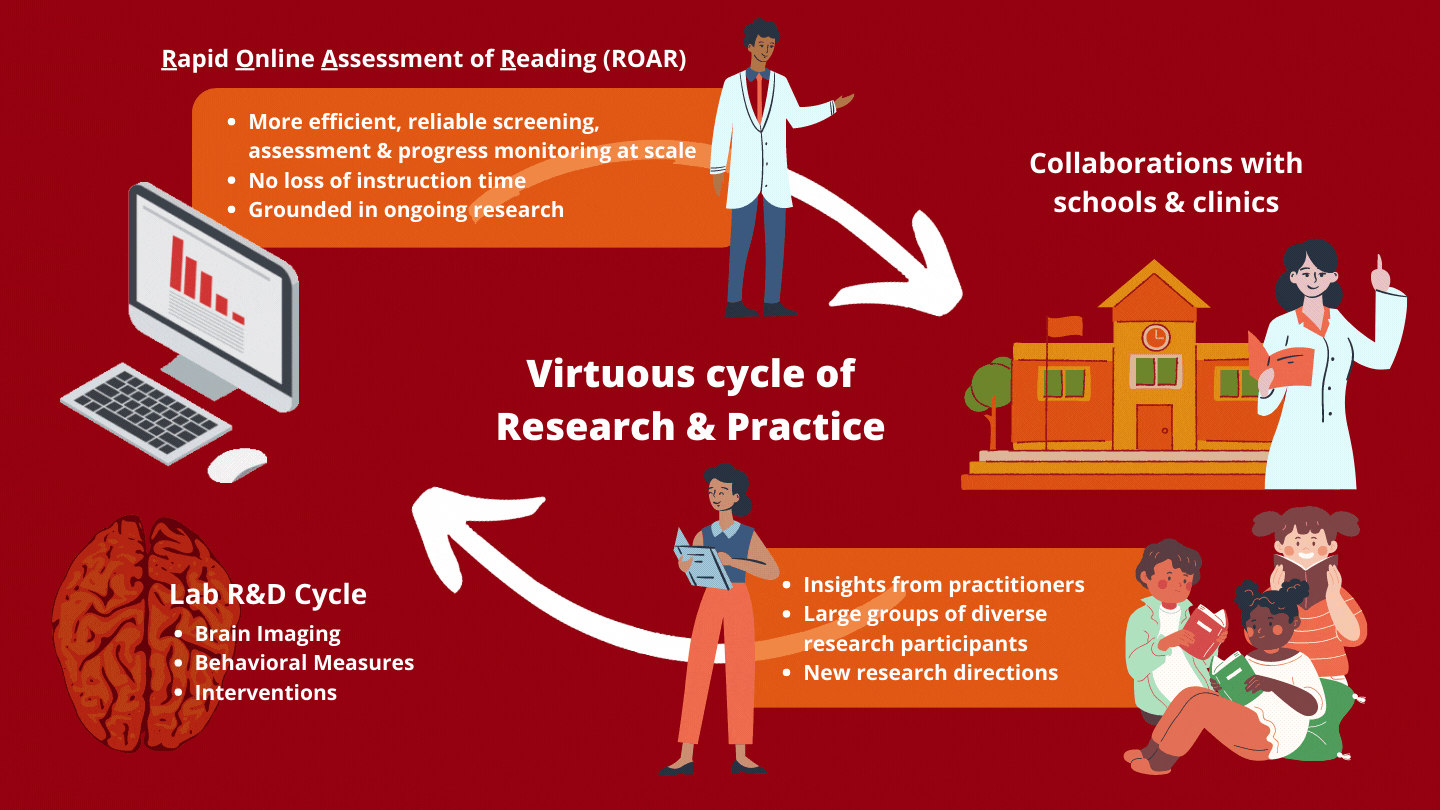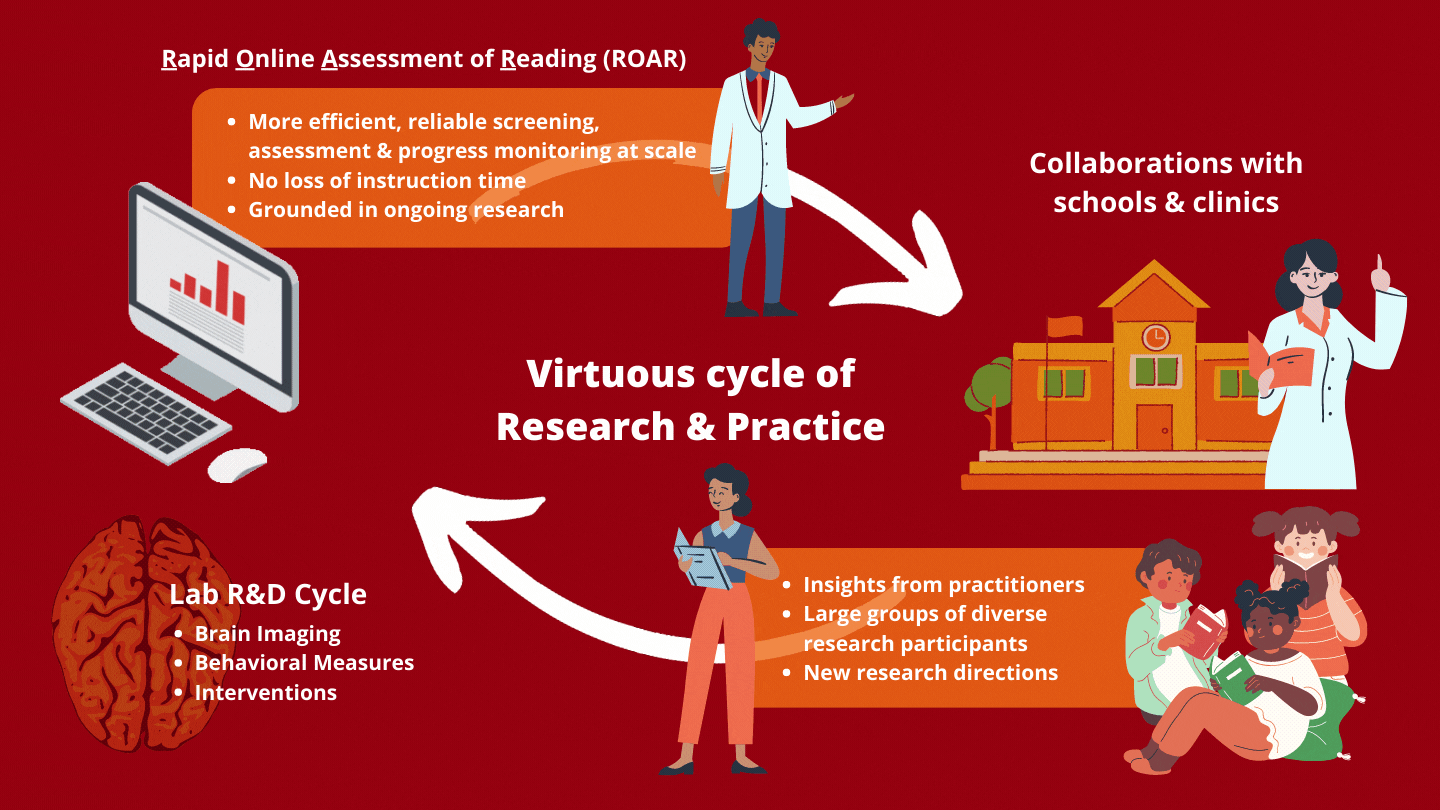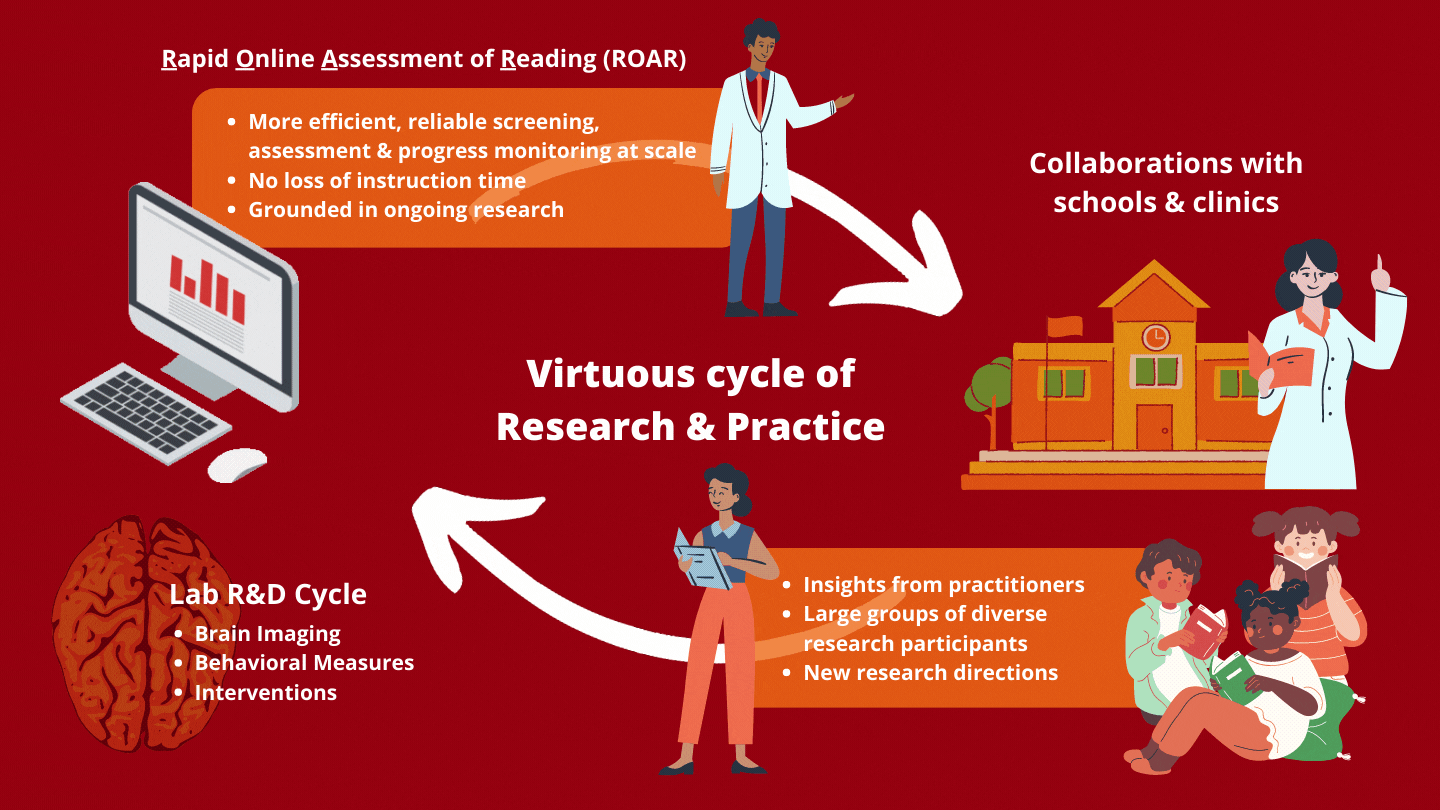
Active R&D
Together with our partners, we are developing subtests and co-designing the platform to meet the needs of educators, clinicians, and other researchers.